데이콘 Image Segmentation 대회 참가기
안녕하세요? 오랜만에 일상글을 씁니다 하하 오늘은 한 3주간 매진해있었던 데이콘 대회 참가기를 써보려고 합니다 ㅎㅎ
나름 재밌었었고.. 제대로? 해본 첫 대회여서 기록을 남기고자!! 이렇게 글을 씁니다. 부족한 점이 있다면 언제나 피드백 환영입니다!!
데이콘이란?
데이콘 링크 : dacon.io/
데이터사이언티스트 AI 컴피티션
1만 AI팀이 협업하는 인공지능 플랫폼.
dacon.io
캐글의 한국버전이라고 생각하면 좋을 것 같습니다. 여러가지 데이터 분석 대회가 올라오고... 정말 캐글같은 사이트입니다. 국내에서 운영되는 사이트다 보니 국내 대회가 많습니다.
올라오는 대회의 종류도 정말 다양한데, 저는 어쩌다보니 아래 K-fashion AI 경진 대회를 참가하게 되었네요.하하 그냥 경험삼아?! 참가했습니다.
두둥 첫 대회 !?

대회 정보 : K-fashion AI 경진대회
이 K-fashion AI 경진대회에 나갔습니다. instance segemtation의 대회였고, mmdetection이라는 툴을 사용해서 참가할 수 있었어요. 데이터는 json 파일로 되어있고 COCO API를 사용한 데이터였습니다.
사실.. 모든게 처음이었습니다. COCO api는 또 무엇이고.... MMdetection이란 또 무엇인가..
그동안 segmentation에는 sementic과 instance가 있고 MaskRCNN을 사용한다~ 이런게 있다~ 라고만 알고 있었는데 이렇게 대회에 참가하니 새삼 정말 아무것도 모르는구나! 를 실감했습니다 ㅎㅎ
그래서 찾아보니 COCO Api는 object detection, segmentation 등을 위한 데이터셋으로 이런 류의 대회에 자주 사용되는 데이터 셋이었습니다 .구글이 공개했던 tensorflow object detection api에서도 coco dataset으로 학습시킨 모델이 있다고 하네요. COCO 데이터셋에 대한 자세한 내용은 아래 ukayzm님의 블로그 게시글을 확인하시면 좋을 것 같습니다.
애초에 데이터가 잘 되어있어서.. 사실 여러번 모델 학습시키고 돌려보면 되는 대회였습니다. 하하
Just Do It!
그래서 일단 시작해보았습니다. 주최측에서 baseline 코드를 제공하더라구요. ㅎㅎ 어찌저찌 돌려보자! 했습니다.
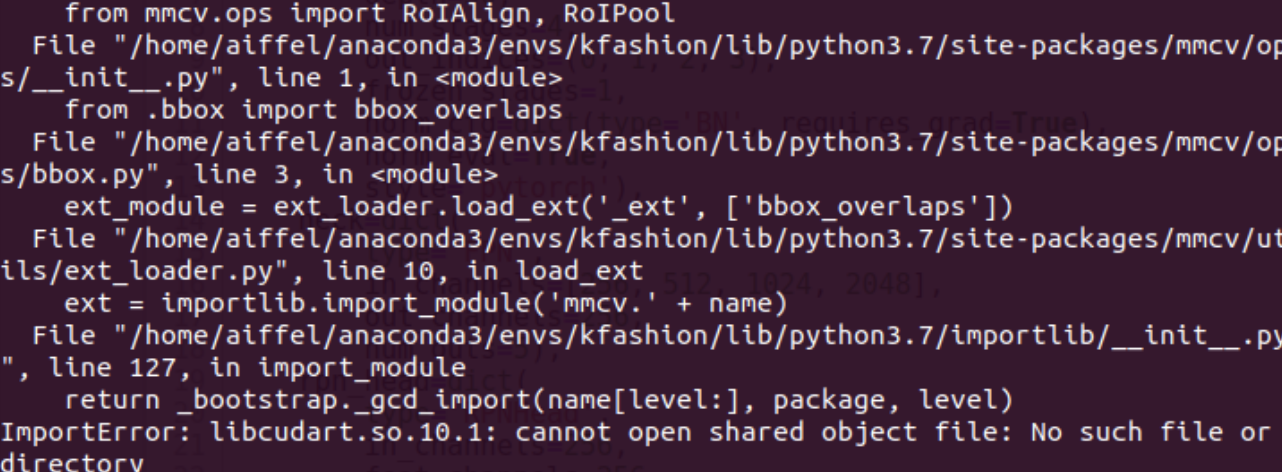
네 바로 될리가요 ㅎㅎㅎㅎㅎㅎㅎㅎㅎ
바로 import error가 나왔습니다 버전이 조금 심하게(?) 꼬였었습니다.
결론적으로 말하자면, mmdetection은 나중에 2.4.0 버전을 사용했고 cuda는 10.2를 설치했습니다. torch는 1.5.0, mmcv-full은 cuda 버전에 맞게 또 설치해줘야 했습니다.
이것을 알기까지가.. 참 힘들더라구요.. 저는 뭣도 모르고 cuda 11을 깔았다가 downgrade를 했습니다. 근데 나중에 살펴보니 명령어를 nvcc -V를 입력했을때, nvidia-smi 를 입력했을때, torch에서 쿠다 버전을 확인할때 모두 다 다른 버전으로 나오더라구여 ㅎ 아직도 뭐가 뭔지 잘 모르겠지만.. 결론적으로 말하자면 10.2를 사용했습니다.
다시 어찌저찌.. 학습을 시켜보자..!
어쨌거나 저쨌거나 mmdetection에서 가장 중요한 부분은 바로 config 파일 설정이라고 생각합니다. 이는 mmdetection의 config 디렉토리에 있습니다. 저는 따로 default.py 이런 식으로 ./config/_base/ 디렉토리에 config 파일을 만들어주었습니다.
그리고 돌려보았습니다.
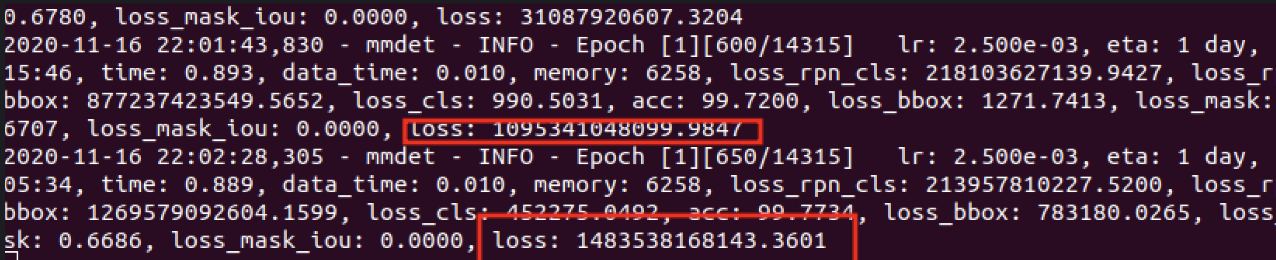
loss가 1조가 넘게 나오네요 ㅎㅎ
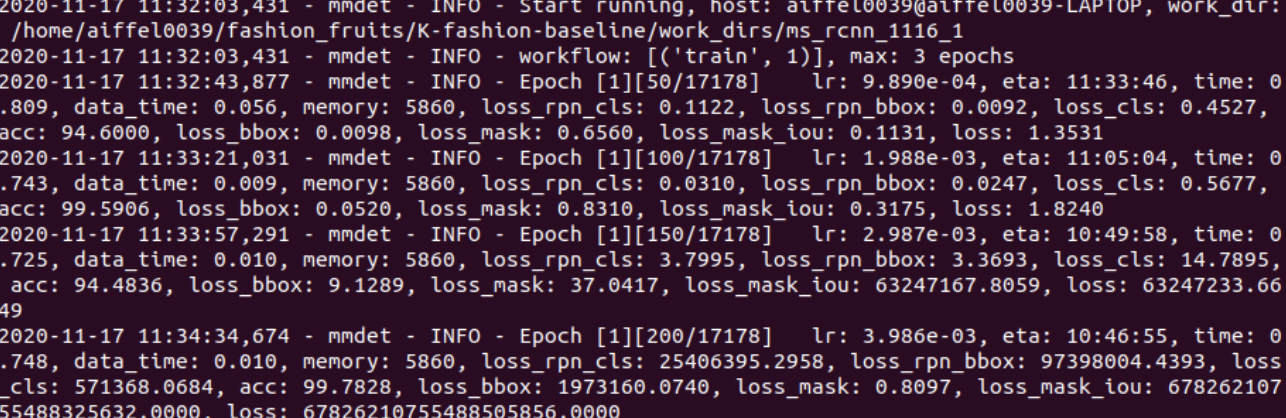
뭔가를 그래서 손보았습니다. 찹찹 이미지는 계속 이상한 결과를 보여드리는데, 나중에는 학습이 조금 잘 되었긴 했습니다.
MaskRCNN을 제일 먼저 시도해보았습니다. 결과는?
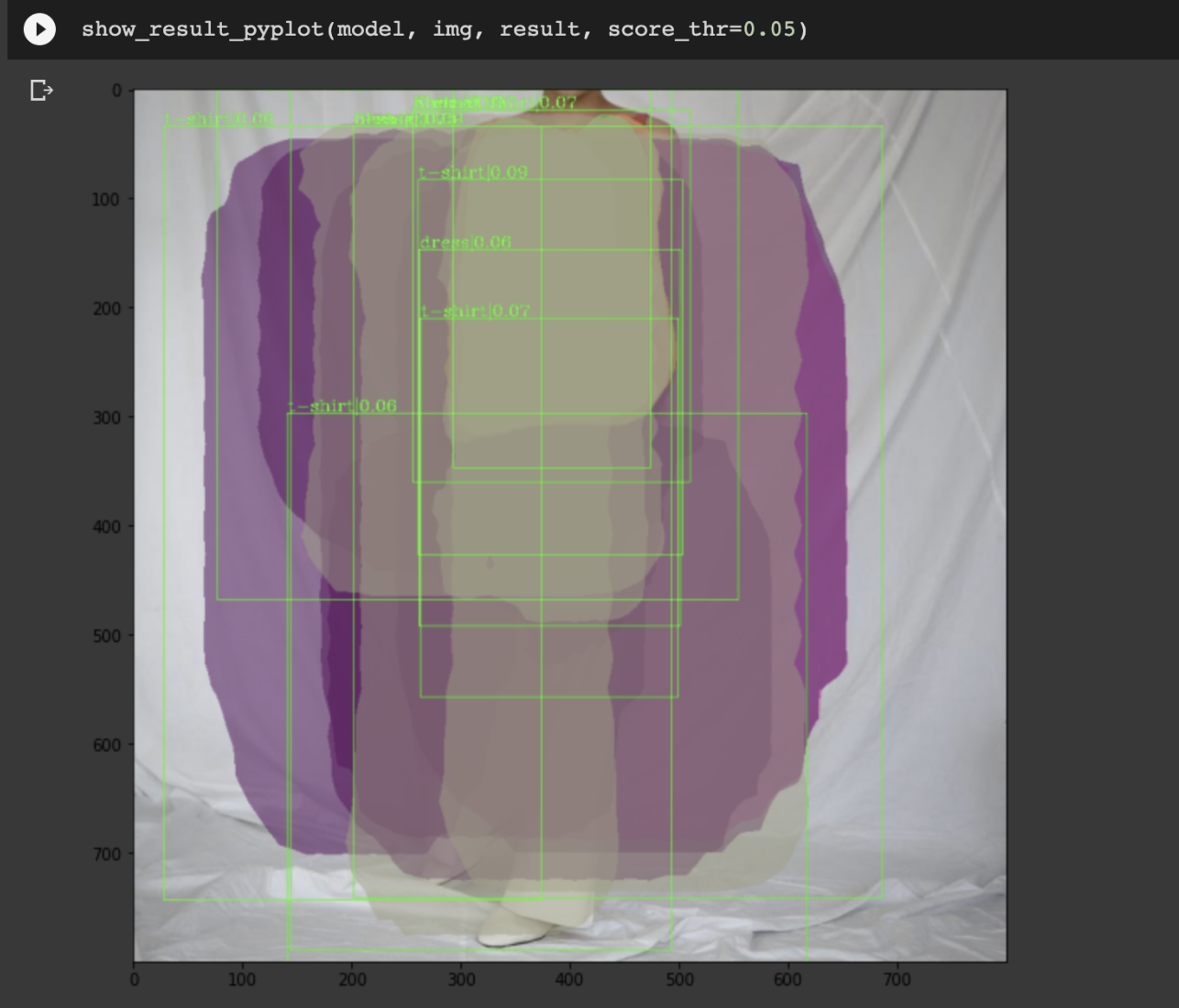
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
휴.. 재밌네요..
정확하게 엉망입니다.
근데 모델이 뭐가 뭐지..?
이것 저것 모델을 사용해보긴 했습니다. 그냥 config 파일을 슥 고치기만 하면 되긴 했는데, 정확히 뭐가 무엇인지 잘 모르겠더군요.
그래서 시작한 것이 먼저 논문을 살펴보자는 것이었습니다. 저희는 3가지 논문을 선정해서 다같이 논문 리뷰를 하며 알아갔습니다. 3가지 논문은 너무나도 대표적인 R-CNN, Faster R-CNN, Mask R-CNN 이었습니다.
논문 리뷰는.. 뭐 캐쥬얼하게 진행했던 것 같습니다. 각자 공부하고 하나씩 다같이 읽어보면서 서로가 이해하고 있는 것이 정확한 것인지를 알아가는 방식으로 진행했습니다.
그래 코랩..! 코랩 프로를 써보자..!
사실 학습이 잘 안되는것도 물론이거니와, 가장 중요한(?) 문제는 학습에 시간이 너무나도 오래걸린다는 점이었습니다. batch사이즈를 늘리면 좋았지만 금방 Out of memory 에러가 나더라구요. 템빨의 한계를 다시 한번 느끼면서 어떻게 하면 좋을까.. 고민을 해보았습니다.
첫번째는 클라우드 서비스를 활용하는 방법이 있었습니다. 그런데 저는 이미 GCP 300크레딧 무료로 주는 것을 사용해버렸고... 다른 팀원의 아이디로 GCP를 시도해보았으나 환경 셋팅을 하는 것이 로컬보다 더 잘 되지 않아서 깔끔하게 포기하기로 했습니다. ^____^
그렇게 생각해 낸 두번째 대안이 바로 코랩 프로였습니다.

좋은 성능의 GPU를 쓸 수 있다는 점, 그리고 구글 드라이브와 마운트가 용이하다는 점이 매우 매력적이었습니다. 그래서 바로 결제! (한달에 12000원 꼴이라고 생각하면 좋습니다.) 눈누난나 이사를 가기 시작했죠. 공유 드라이브를 하나 파서 팀원들을 초대하고 같이 하면 좋겠다고 생각하여 그리 했습니다.
물론 그 과정도 마냥 쉽지는 않았습니다...... 왜냐하면 데이터가 매우 컸기 때문이죠... 데이터셋을 업로드하고 압축을 푸는 데에만 또 한참의 시간이 걸렸습니다. ㅎ...
그렇게 이사간 코랩에는 또 다른 문제점이 있었는데,, 바로 I/O 에러였습니다.

롸...? I/O 에러요..?
이게 파일이 엄청 많이 있는 구글 드라이브에 너무 단시간에 많은 엑세스 요청을 하면 이렇게 접근을 제한하는 것 같더라구요. 그래서 일정 시간 (하루 반정도?) 지나야 이 제한이 풀렸던 것 같습니다.
똥줄이 타기 시작했습니다... 결국 코랩을 제대로 사용을 못했습니다.
그래도 다행인건 한두번은 학습을 했다는 점입니다. ㅎㅎ 12000원의 결과물이 학습한 것이었죠. (그래도 두둑해진 내 드라이브...)
모델을 바꿔보자
근데 가장 근본적인 문제점이 있었습니다. 그것은 바로 스코어가 아무리 해도 올라가지 않았다는 점입니다.
이는 모델에 그 문제가 있다고 생각했습니다. MaskRCNN을 사용했는데, 비슷한 계열로 Cascade Mask RCNN도 있고... yolo도 있고 여러가지가 있었죠. backbone 네트워크를 바꿔보고 이 모델 저 모델을 사용해보아도 성능은 그닥 나아지지 않았습니다.
그러다가 토론 게시판에 올라온 하나의 글! 비슷한 캐글의 대회에서 우승한 사람의 코드를 어떤 분이 올려주셨습니다. 헉!
- 우승자 노트북 - iMaterialist (Fashion) 2019 at FGVC6 : [Update] 1st place solution with code
- 해당 위너가 사용했던 augmentation tool : github.com/albumentations-team/albumentations
이거다!! 바로 적용해보았습니다.
근데 엄밀히 말해서 똑같이 적용을 하지는 못했습니다. 긁적.. 왜냐하면.. 어떻게 하는지 몰랐기 때문이죠. 아시는 분이 있으시다면 댓글 달아주시면 감사하겠습니다.....
그래서 저희가 사용했던 모델은 Hybrid Task Cascade 모델이었고, Backbone 네트워크로 ResNeXt-101-64x4d-FPN 모델을 사용했습니다. pretrained 모델을 사용하고 싶었으나 이 모델이 12기가가 넘더라구여.. ㅎㅎ 그래서 그냥 쌩으로 학습을 시켰습니다.
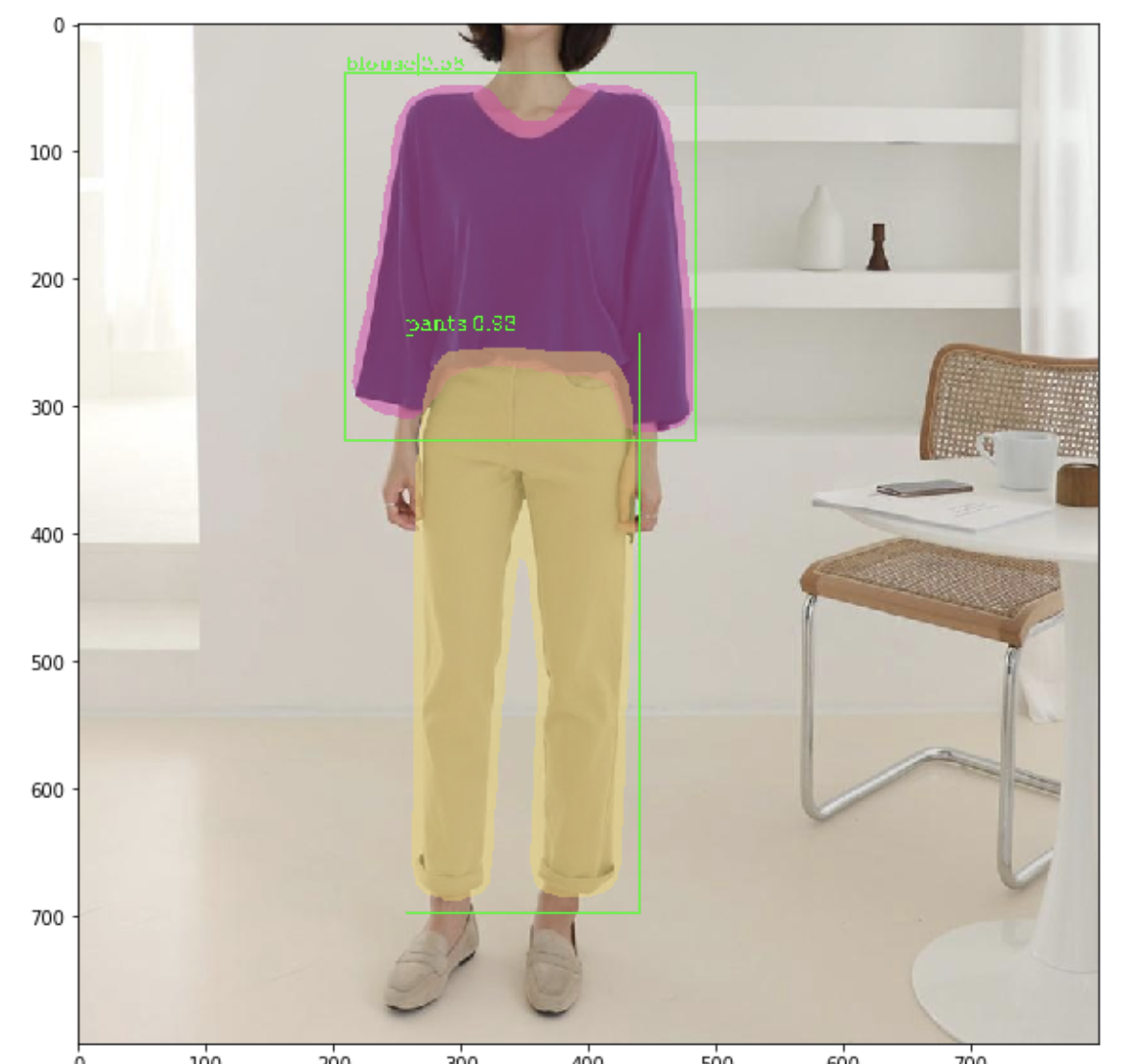
그 결과.. 이정도로 학습이 잘 되었습니다!! 장족의 발전!
결론적으로 위 모델이 가장 좋은 성능을 보였습니다. (예~) 그래도 순위권에 드는 점수는 아니였죠. (우...ㅠ)
그래도 어쨌거나 저쨌거나 좋은 경험이었고 미래에 다시 추억하고자? 그리고 저와 같이 데이콘 대회를 참가하시는 분들을 위해 경험을 공유하고자 이렇게 글을 남깁니다. ㅎㅎ 언제든지 궁금한점이 있으시다면 댓글 남겨주세요 :)