Tensorflow Lite에서 Delegate란? - GPU Delegate
안녕하세요~! 이번 포스팅에서는 오픈소스 프로젝트를하며 계속 등장하는 개념인 delegate에 대한 내용입니다. 대충 이해하고 있는 것으로는... 뭔가 썸띵.. 머신러닝 모델을 gpu에서 돌릴 수 있게 하는 cuda 같은 것이라고 이해하고 있었는데(??) 이런 저런 내용을 조금 정리해 보도록 하겠습니다.
TFLite Delegate란?
Delegate는 '대리자'라는 뜻으로, TFLite Delegate는 그래프 실행의 일부 또는 전체를 다른 executor에 위임하는 방식입니다. 그래프 실행을 여기 말고 저기서 할 수 있도록 하는 친구들이라는 것이죠.
모바일 디바이스에서 모델을 돌릴 때, 컴퓨팅이 많은 머신러닝 모델에 대한 추론을 실행하는 것은 컴퓨팅파워 및 제한된 전력으로 인해 리소스가 많이 필요합니다. 그래서 CPU에 의존하는 대신 일부 기기에 존재하고 있는 GPU또는 DSP와 같은 하드웨어 가속기에 돌리도록 "위임"하여 성능과 에너지 효율성을 높일 수 있게 하는 것이 delegate입니다.
Delegate 동작 원리
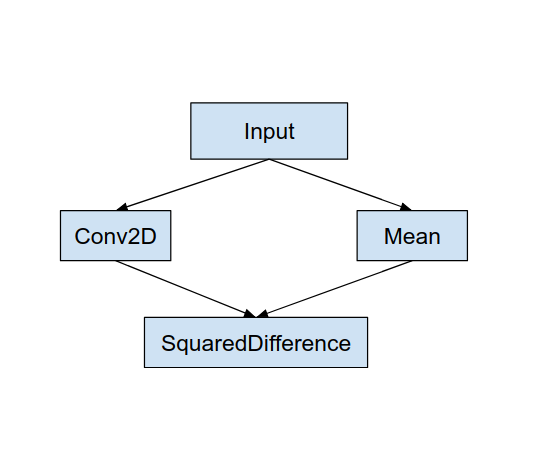
만약 이런 모델 그래프가 있다고 가정해 봅시다. 여기서 Conv2D연산과 Mean 연산을 GPU에서 수행하게 된다면 더욱 빠르고 전력을 절약할 수 있을 것 같습니다. 여기서 Delegate(=MyDelegate)를 사용하면 그래프를 아래와 같이 보이도록 할 수 있습니다.

훨씬 깔끔해지죠? Conv2D 연산과 Mean을 Delegate가 수행하도록 함으로써 훨씬 간편하게 정리할 수 있습니다.
일반적으로 delegate에서 기본으로 전환할 때 마다 오버페드가 있으므로 대리자가 여러개의 하위 그래프를 처리하지 않도록 하는 것이 좋습니다. 메모리 공유가 언제나 안정적인 것은 아니라고 하네요 ㅎㅁㅎ
TFLite에서 제공하고있는 내장 Delegate - GPU Delegate
Tensorflow Lite에서는 4가지 delegate를 제공하고 있는데요, iOS, 구형 안드로이드, 신형안드로이드 등등 delegate가 있지만 제가 가장 자주 많이 사용하는 것은 GPU Delegate입니다!
GPU Delegate는 Android와 iOS 모두에서 사용할 수 있는 크로스 플랫폼으로, GPU를 사용할 수 있는 32bit 및 16bit 부동 기반 모델을 실행하도록 최적화되어 있습니다. 아무래도 GPU를 사용하다보니 속도 면에서 가장 두드러진다는 특징이 있고, 반복 연산을 효율적으로 처리하다보니 CPU로 실행될 때 보다 전력을 덜 소비하고 발열도 덜 발생합니다. TFLite GPU에서는 RELU, SOFTMAX, PAD, CONV_2D, FC, LSTM, LOGISIC 등 대부분 자주 사용되는 연산을 모두 지원하고 있습니다.
Android(C/C++)에서 GPU Delegate를 사용해보자
Android에서 Tensorlfow Lite GPU의 C/C++를 사용하는 경우, GPU Delegate는 TfLiteGpuDelegateV2Create()로 만들고 TfLiteGpuDelegateV2Delete()로 제거할 수 있습니다.
// Set up interpreter.
auto model = FlatBufferModel::BuildFromFile(model_path); // 모델 불러오기
if (!model) return false;
ops::builtin::BuiltinOpResolver op_resolver;
std::unique_ptr<Interpreter> interpreter;
InterpreterBuilder(*model, op_resolver)(&interpreter);
// NEW: Prepare GPU delegate.
auto* delegate = TfLiteGpuDelegateV2Create(/*default options=*/nullptr); // gpu delegate 가져오기
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; //인터페이스에 delegate입력해서 gpu 사용하도록
// Run inference.
WriteToInputTensor(interpreter->typed_input_tensor<float>(0));
if (interpreter->Invoke() != kTfLiteOk) return false;
ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0));
// NEW: Clean up.
TfLiteGpuDelegateV2Delete(delegate);TfLiteGpuDelegateOptionsV2를 살펴보고 사용자 정의 옵션이 있는 대리자 인스턴스를 만듭니다. TfLiteGpuDelegateOptionsV2Defualt()를 사용하여 기본 옵션을 초기화 한 다음 필요에 따라 수정할 수 있습니다.
Android C/C++용 TFLite GPU는 Bazel 빌드 시스템을 사용할 수 있습니다.
bazel build -c opt --config android_arm64 tensorflow/lite/delegates/gpu:delegate # for static library
bazel build -c opt --config android_arm64 tensorflow/lite/delegates/gpu:libtensorflowlite_gpu_delegate.so # for dynamic library다음에는 Android에서 TFLite모델을 돌릴 때 GPU Delegate를 이용하여 추론하는 방법을 정리해보겠습니다ㅎㅎ
Reference....
'IT Trends' 카테고리의 다른 글
| 구글 Gemini에 관해 이모저모 (0) | 2023.12.16 |
|---|---|
| Bazel이란? (0) | 2021.05.24 |
| Google I/O 2021 키노트를 듣고 몇가지 흥미로운 것들 (0) | 2021.05.20 |
| 요즘 제일 힙한 프로그래밍 언어, Rust (0) | 2021.04.26 |
| 완전 편한 Data Science용 Python 웹 프레임워크, Streamlit (2) | 2021.04.09 |